
Leventcan Gültekin


API sistemi (Application Programing Interfaces - Uygulama Programlama Arayüzleri) en kısa hali ile iki yazılımın veya veritabanının birbiri ile sorunsuz çalışabilmesini, en sağlıklı bir şekilde birbiri ile iletişime geçmesini, birbiri ile veri alışverişi yapabilmesini sağlayan yapılara verilen isimdir.
R ekosistemi içerisinde geliştirilen bazı paketler kullanarak çeşitli kurum ve veri sahiplerinin ürettiği verilere API’ler kanalıyla kolayca erişilebilmektedir. Bu veritabanları içerik olarak çok zengin ve büyük veri tabanlarıdır.
R kütüphanelerin sağladığı en büyük kolaylık ise API’lerin yanıt olarak gönderdiği XML ve JSON dosyalarının paket içerisindeki çeşitli fonksiyonlar tarafından işlenerek doğrudan düzenli tablolara çevirilmesidir.
Bu blog paylaşımımda sosyal bilimciler için çok kritik konumda olan Dünya Bankası, OECD ve Avrupa Birliği tarafından derlenenen verilere ilişkin veritabanlarına API’ler kanalıyla nasıl erişilebileceğine kısaca değinmeye çalışacağım.
Dünya Bankası’nın geliştirmiş API ile bir çok ülke detayında farklı sektör ve temadaki veriye kolaylık ulaşılabilmektedir. Data360r paketi ile bu işlem gerçekleştirilmektedir. Yapacağım bu çalışmada da veri manipülasyon işlemlerinde dplyr ve tidyr paketlerini, görselleme işlemlerinde ise ggplot2 paketini kullanacağım.
#Gerekli kütüphanelerin aktif hale getirilmesi
library(data360r)
library(dplyr)
library(tidyr)
library(ggplot2)
library(ggthemes)
library(plotly)
library(forcats)Dünya Bankası, bu paket ile tc ve gov olmak üzere iki ayrı veritabanına erişime olanak sağlamaktadır. Bunların içerikleri ve göstergeler de birbirlerinden farklıdır. Çok fazla veri olduğu için öncelikle metaveri bilgisini data frame’e kaydediyoruz. Bu data frame nesnelerinin içeriğine kendi IDE’nizden bakarak hangi göstergeyi kullanmak istediğiniza karar verebilirsiniz.
#Metaverinin oluşturulması
df_indicators_tc <- get_metadata360(site="tc", metadata_type = "indicators")
df_indicators_tc <- df_indicators_tc %>% arrange(id)
df_indicators_gov <- get_metadata360(site="gov", metadata_type = "indicators")
df_indicators_gov <- df_indicators_gov %>% arrange(id)Veri setlerinde hangi ülkelin olduğu ve bu ülkelere ilişkin referans kodları öğrenmek için de aşağıdaki komutu yazabiliriz.
#Ülke kodlarının alınması
df_countries <- get_metadata360(metadata_type = 'countries')Aşağıdaki örnekte Türkiye için toplam milli tasarufların GSYH’ye oranını alalım
#Türkiye için verinin çekilmesi
tur_data <- get_data360(site = "tc", country_iso3 = c("TUR"),
indicator_id = c(983),
output_type = "long")#Zaman serisi grafiğinin oluşturulması
ggplotly(
ggplot(data = tur_data,aes(x=Period, y=Observation, group=1)) +
geom_line(size=1)+geom_point() +
scale_x_discrete(breaks = seq(1960,2016,2)) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
labs(x="", y= "Tasarruf/GSYH")
)Aşağıdaki örnekte ise bazı ülkerininde verilerini alıyoruz ve bunlarıda grafiğimize ekliyoruz.
#Dört ükeye ilişkin verinin çekilmesi
countries_data <- get_data360(site = "tc", country_iso3 = c("TUR","CHN","USA","RUS"),
indicator_id = c(983),
output_type = "long")#Dört ülkeli zaman serisi grafiğinin oluşturulması
ggplotly(
ggplot(data = countries_data,aes(x=Period, y=Observation, group=`Country ISO3`,colour=`Country ISO3`)) +
geom_point(size=1)+ geom_line()+ scale_x_discrete(breaks = seq(1960,2016,2)) +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
plot.margin = unit(c(0,2,1,1), "cm")) +
labs(x="", y= "Tasarruf/GSYH")
)Bu verileri tek bir koordinat düzleminde göstermek yerine ülkeye göre dağıtarak da gösterebiliriz. Veriler incelendiğinde Türkiye’de ve özellikle Çin’de tasarruf oranlarındaki artış göze çarpmaktadır.
#Dört ülkeli zaman serisi grafiğinin oluşturulması
ggplotly(
ggplot(data = countries_data,aes(x=Period, y=Observation, group=1)) +
geom_line() + scale_x_discrete(breaks = seq(1960,2016,10)) +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
plot.margin = unit(c(0,0,1,1), "cm")) +
labs(x="", y= "Tasarruf/GSYH") + facet_grid(. ~ `Country ISO3`)
)OECD verilerine ise OECD paketi ile erişilebilebilmektedir.
library(OECD)Hangi veriyi aradığımız hakkında herhangi bir fikrimiz yoksa, ilk olarak bütün alt veritabanı bilgilerini bir dataframe’e kaydedip, onun üstünden belirli metin filtreleri ile arama yapabiliriz. Aşağıdaki kodda tüm alt veritabanları listesi kaydediliyor ve ardından “verimlilik” ifadesinin geçtiği alt veritabanlarının arıyoruz.
dataset_list <- get_datasets()
search_dataset("Productivity", data = dataset_list)
## # A tibble: 9 x 2
## id title
## <fct> <fct>
## 1 PDYGTH Labour productivity growth in the total economy
## 2 LEVEL Labour productivity levels in the total economy
## 3 MFP Multi-factor Productivity
## 4 ULC_EEQ Unit labour costs and labour productivity (employment based), T~
## 5 PDBI Productivity by industry (ISIC Rev.3)
## 6 PDB_LV Level of GDP per capita and productivity
## 7 PDB_GR Growth in GDP per capita, productivity and ULC
## 8 PDBI_I4 Productivity and ULC by main economic activity (ISIC Rev.4)
## 9 EAMFP Environmentally Adjusted Multifactor ProductivityEldeki verileri incelediğimde ekonomideki iş gücü verimliliğini ifade eden LEVEL id’ sine sahip alt veritabanını kullanmaya karar veriyorum.
dataset <- "LEVEL"Veritabanını indirmeden önce verinin yapısına bakmakta fayda bulunmaktadır. str fonksiyonu ile verinin yapısını incelediğimiz “list” yapısı halinde metaveri bilgilerini görebiliyoruz. Veriyi indirmeden önce bu veri filtreleri ile indirilecek dosya büyüklüğü kısıtlanabilir. Alternatif olarak tüm veri setini indirip, ardından base R fonksiyonları ile filtreleme de yapılabilir fakat bu yöntem dosyası indirme süresini uzatacaktır.
dstruc <- get_data_structure(dataset)
str(dstruc, max.level = 1)
## List of 6
## $ VAR_DESC :'data.frame': 6 obs. of 2 variables:
## $ VAR :'data.frame': 8 obs. of 2 variables:
## $ COU :'data.frame': 38 obs. of 2 variables:
## $ TIME :'data.frame': 1 obs. of 2 variables:
## $ OBS_STATUS :'data.frame': 23 obs. of 2 variables:
## $ TIME_FORMAT:'data.frame': 5 obs. of 2 variables:Tek bir değişkenle çalışacağım için dosya büyüklüğü sorununu ihmal ediyorum ve tüm veri setini filtre kullanmadan indiriyorum. Devamında dplyr paketi yardımıyla gerekli filtrelemeleri yapacağım.
df_productivity <- get_dataset(dataset = dataset)
head(df_productivity)
## # A tibble: 6 x 4
## VAR COU TIME obsValue
## <chr> <chr> <chr> <dbl>
## 1 PPPS AUS 2012 1.46
## 2 HRSA AUS 2012 1685
## 3 EMPT AUS 2012 11594
## 4 HRST AUS 2012 19538
## 5 PDYC AUS 2012 53
## 6 PDYU AUS 2012 82.7Veriyi indirildiğinde VAR değişkeni dikkate çarpmaktadır. Buradaki VAR değişkeni veritabanındaki farklı değişkenleri ifade etmektedir. Bunların ne olduğu aşağıdaki sorgu ile anlyabiliriz.
dstruc$VAR
## id label
## 1 PPPS Purchasing Power Parities for total GDP, national currency per USD
## 2 HRSA Average hours worked per person
## 3 EMPT Total employment (number of persons engaged)
## 4 HRST Hours worked for total employment
## 5 PDYC GDP per hour worked, current prices, USD
## 6 PDYU GDP per hour worked as % of USA (USA=100)
## 7 GDNC Gross Domestic Product, current prices, national currency millions
## 8 GDUS Gross Domestic Product, current prices, USD millionsSonuçları incelediğimde Çalışılan Saat Başına GSYH Tutarını (Dolar) ifade eden PDYC değişkenini kullanmaya karar veriyorum ve verisetimi buna göre filtreliyorum
df_productivity <- df_productivity %>% filter(VAR == "PDYC")
df_productivity$COU <- as.factor(df_productivity$COU)Filtreleme işlemini tamamladıktan sonra değişkene ilişkin yalnızca 2012 yılı verilerinin olduğunu görüyorum. Artık veri görselleştirmeye hazır durumdadır.
ggplotly(
ggplot(df_productivity) + geom_bar(aes(x= fct_reorder(COU, obsValue,.desc = TRUE), y= obsValue),
alpha=0.7, fill="green4", stat = "identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
plot.margin = unit(c(0,0,1,1), "cm")) +
labs(x="", y= "GSYH / Çalışılan Saat")
)Eurostat’ın API kanalıyla sunduğu verilere erişmek için eurostat paketi kullanılabilmektedir. Eurostat veritabanlarında yer alan verilere ilişkin metaveriye erişmek için aşağıdaki fonksiyon kullanılabilir.
library(eurostat)
library(stringr)
toc <- get_eurostat_toc()
#Metaverinin incelenmesi
colnames(toc)
## [1] "title" "code"
## [3] "type" "last update of data"
## [5] "last table structure change" "data start"
## [7] "data end" "values"
head(toc)
## # A tibble: 6 x 8
## title code type `last update of~ `last table str~ `data start`
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Data~ data fold~ <NA> <NA> <NA>
## 2 Gene~ gene~ fold~ <NA> <NA> <NA>
## 3 Euro~ euro~ fold~ <NA> <NA> <NA>
## 4 Busi~ ei_b~ fold~ <NA> <NA> <NA>
## 5 Cons~ ei_b~ fold~ <NA> <NA> <NA>
## 6 Cons~ ei_b~ data~ 29.11.2018 29.11.2018 1980M01
## # ... with 2 more variables: `data end` <chr>, values <chr>Metaverinin yer aldığı toc dataframe nesnesi RStudio’dan da detaylı incelenip, hangi verilerin olup olmadığı görülebilir. Kullanılacak olan değişken belirlendikten sonra toc dataframe dosyasından hangi değişkene ilişkin code değerinin elde edilmesi gerekmektedir. Dataframe’i inceledikten sonra NUTS3 bölgelerine göre nüfus yoğunluğu verisetini kullanmaya karar veriyorum.
id <- "demo_r_d3dens"
dat <- get_eurostat(id, time_format = "num")
head(dat)
## # A tibble: 6 x 4
## unit geo time values
## <fct> <fct> <dbl> <dbl>
## 1 HAB_KM2 AL 2016 105.
## 2 HAB_KM2 AL0 2016 105.
## 3 HAB_KM2 AT 2016 106.
## 4 HAB_KM2 AT1 2016 165.
## 5 HAB_KM2 AT11 2016 77.1
## 6 HAB_KM2 AT111 2016 54.4Verisetinde farklı mekansal ölçekte ve yıllara göre kırınımlar bulunmaktadır. Bu sebeple verisetini yalnızca 2016 yılı ve NUTS-3 bölgeleri olacak şekilde filtreliyorum.
dat <- dat %>% filter(time == 2016) %>%
filter(str_length(geo)==5) #Şehir adlarının yerleştirilmesi
city_labels <- label_eurostat(dat, fix_duplicated = T)
dat$geo_name <- city_labels$geoYukarıda gösterdiğim diğer örneklerden farklı olarak bu örnekte veriyi harita üzerinde görselleştirmek istiyorum. Fakat harita üzerinde görselleştirmeden önce Avrupa ülkelerinin NUTS-3 ölçeğinde vektör harita verisine ihtiyaç bulunmaktadır.
AB komisyonunun mekansal verilerden sorumlu GISCO biriminin mekansal verilerine de eurostat paketi aracılığıyla ulaşılabilmektedir.
eu_map <- get_eurostat_geospatial(output_class = "sf", resolution = "60",
nuts_level = 3)Verideki değerler sürekli sayısal değerlerdir. Harita üzerinde görselleştirmede kolaylık sağlaması için bu değerleri belirli aralıklarda grupluyorum.
eu_map <- eu_map %>% left_join(dat, by = c("NUTS_ID" = "geo"))
eu_map$category <- cut(eu_map$values, c(0,25,50,100,150,200,500,1000,5000,20000))Artık geriye ggplot2 ile verilerin görselleştirilmesi kalmaktadır.
ggplot(data = eu_map) + geom_sf(aes(fill = category)) +
coord_sf(xlim=c(-12,44), ylim=c(35,67)) +
scale_fill_brewer(palette = "RdPu", name = "") +
theme(legend.position = c(0.9,0.7),
legend.background = element_rect(fill = "transparent"),
axis.text=element_blank(),
axis.ticks = element_blank()) +
ggtitle("NUTS 3 Bölgelerine Göre Nüfus Yoğunluğu")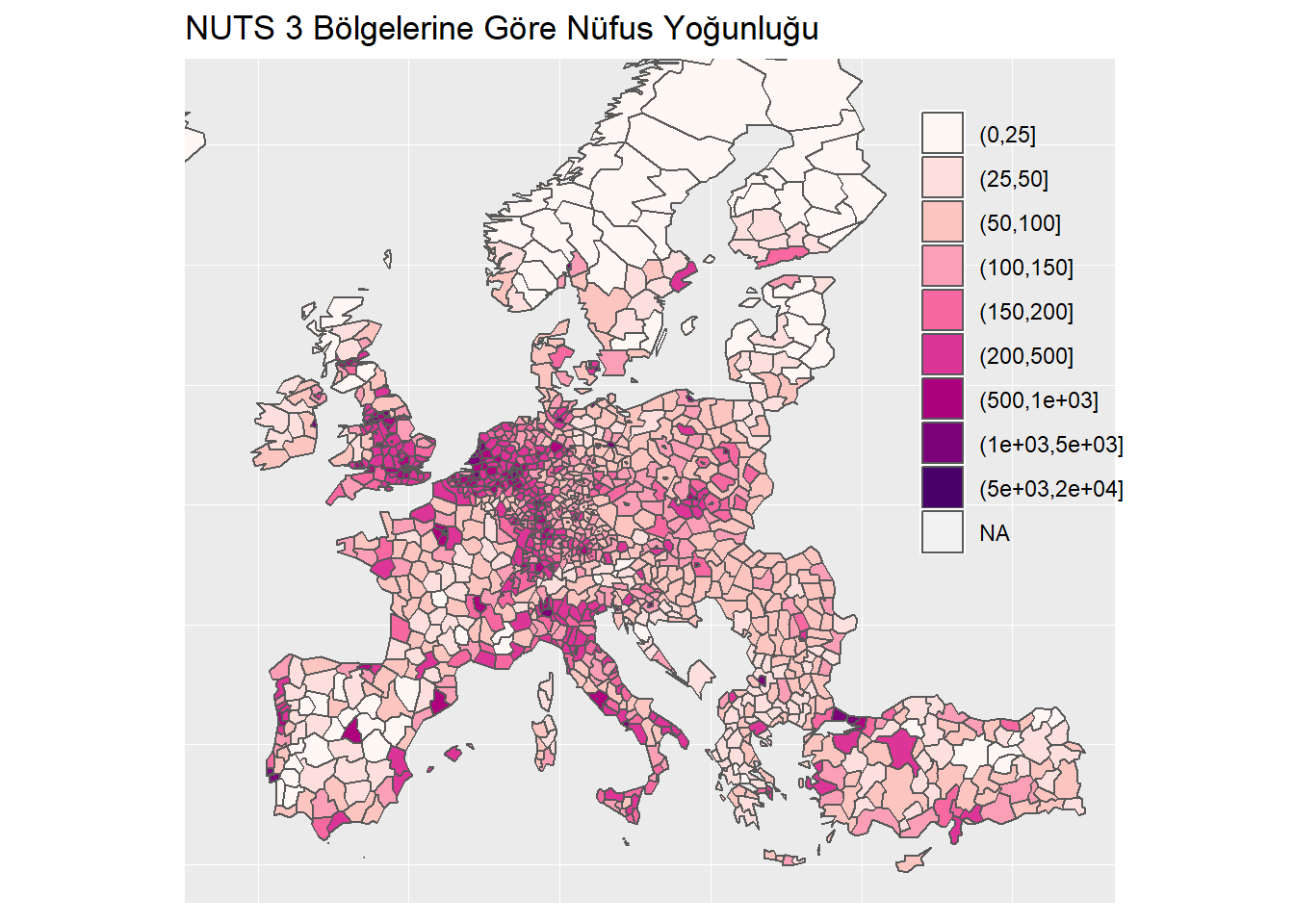
library(leaflet)
bins <- c(0,25,50,100,150,200,500,1000,5000,20000, Inf)
pal2 <- colorBin("plasma", domain = eu_map$values, bins = bins,
reverse = TRUE)
labels <- sprintf(
"<strong>%s</strong><br/>Km2 başına düşen kişi sayısı: %g",
eu_map$geo_name, eu_map$values) %>% lapply(htmltools::HTML)
leaflet(width = 720) %>% addPolygons(data= eu_map, color = "#444444", weight = 1, smoothFactor = 0.5, dashArray="",
opacity = 1.0, fillOpacity = 0.7, fillColor = ~pal2(eu_map$values),
highlightOptions = highlightOptions(color = "white", weight = 2,
dashArray = "",
fillOpacity = 1,
bringToFront = TRUE),
label = labels,
labelOptions = labelOptions(
style = list("font-weight" = "normal", padding = "3px 8px"),
textsize = "12px",
direction = "auto")) %>%
addLegend(pal = pal2, values = eu_map$values, opacity = 0.7, title = NULL,
position = "topright") %>%
addProviderTiles(providers$CartoDB.Positron) %>%
setView(lng = 20.508074,lat = 48.552978, zoom = 3)